Abstract
A critical aspect of a high-quality continuum of patient care is health record documentation. Prediction of poor documentation of electronic health records (EHRs) will help identify physicians who may need early communication to ensure their compliance. Machine learning (ML), a subfield of artificial intelligence, can be used to predict which physicians are non-compliant with health record documentation in an effort to provide high- quality healthcare in the continuum of care and treatment.
Objectives
To employ artificial intelligence tools based on ML classifiers to predict which physicians are likely to be non-compliant with completion of health record documentation in the EHR system. Also, to identify factors affecting the completeness of EHR documentation.
Methods
The information from 90,007 discharged health records was obtained from the EHR system between January 2015 and August 2021, which included physician age, gender, department, and nationality; year of discharge; and patient insurance type. Several ML classifiers in Orange software were used to predict health record documentation completion. Random forest, K-nearest neighbor (KNN), support-vector machines (SVM), neural network, naïve Bayes, logistic regression and AdaBoost are the seven machine learning tools that were employed to test the data’s prediction performance. These classifiers were used to create the best-fit model to predict documentation completeness.
Results
The best-fit model was the random-forest classifier, with AUC = 0.891 and F1 and Recall score = 0.831. Attributes found to be contributing to EHR documentation compliance are year of patient discharge, physicians age group and the department, respectively.
Conclusion
We demonstrate that the random-forest classifier helps hospital management identify physicians who might not complete EHR documentation. This knowledge can be applied to early-intervention methods to ensure that physicians at risk of not completing EHRs become compliant in an effort to enhance documentation adherence for overall improved patient-care quality and continuum of healthcare.
Key words: Documentation, Electronic health record, Machine learning, Quality of patient care.
Introduction
Worldwide, electronic health records (EHRs) and the use of electronic documentation are preferred because they decrease errors. The aim of EHRs is to enhance the healthcare providers’ clinical documentation and decrease the possibility of poor documentation, thereby enhancing the quality and safety of patient care1. Inconsistency and discrepancy in inpatient health records affect the treatment provided to the patient2. Therefore, a critical aspect of a high-quality continuum of patient care is health record documentation.
Incomplete documentation of discharge notes affects the transfer of older patients from hospital to home care3. Moreover, effective communication of discharge documentation between healthcare providers improves patient outcomes and enhances healthcare provider satisfaction4. High rates of hospital readmissions are associated with incomplete discharge summaries5. Incomplete clinical documentation and delays in writing discharge summaries are associated with unplanned hospital readmissions6.
Machine learning (ML) is a part of artificial intelligence whereby computers use a large set of data to identify the relationships between variables by computing algorithms7,8. It is an automated method to analyze data in which algorithms are used to develop models to predict an output variable based on input variables.
ML models have been applied to a variety of medical problems to discover new patterns in existing data9. It has been used to predict radiation pneumonitis in lung cancer patients10, the hospital length of stay at the time of admission11 and surgical site infection after neurosurgical operations12. Moreover, ML has been used to predict readmissions for heart failure patients13 and the amputation rate for patients with diabetic foot ulcers14.
The development of accurate prediction models depends greatly on the presence of complete documentation in patients’ EHR15. ML models were used to identify opioid misuse and heroin use (OM) patients from paramedic trip notes16. They have also been used to detect the keywords “naloxone,” “heroin,” and both combined to identify the true cases of OM. It was also used to predict the documentation of serious illness based on physician notes within 48 hours of intensive care unit admissions for seriously ill patients17.
Currently, the use of ML to assess predictive results in relation to health record documentation completion is rare: few researchers have evaluated ML and health record documentation in relation to specific variables18.
Some physicians are not compliant in completing health record documentation, and hospitals may or may not have policies in place to ensure completion of such records. In this study, we employed ML to help hospital decision makers improve documentation compliance to enable physicians to comply with system health record documentation. We focused on creating a prediction model using ML classifiers to predict which physicians will not complete EHR documentation in the system.
In the hospital understudy, when a patient is admitted to the hospital, the hospital staff completes admission documentation, which includes administrative and clinical information. A physician determines whether the patient is ready for discharge and if so, will complete the admission and discharge documentation in the EHR system. The current problem is in completing the final diagnosis in admission and discharge documentation (Figure 1). This is considered one of the main pieces of documentation that the physician needs to complete. Incomplete documentation impacts continued health support of patients and might affect their safety. Also, it impacts hospitals’ accreditation status because it is one of the accreditation standards.
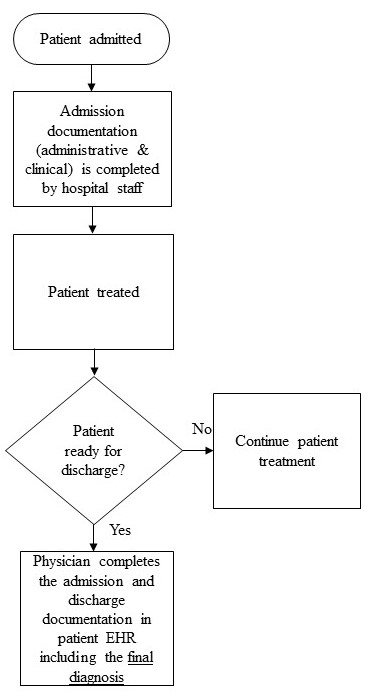
Figure 1. Workflow model for documentation process (current problem).
Material and Methods
Study location and parameters
This study is an experimental study that was conducted at a government hospital in Dammam City, Saudi Arabia. The data included one target variable, the completion of the electronic health record documentation, with two values (1,0) as well as six additional variables: clinical department; the physician’s gender, age, and nationality; the year of discharge; and the patient’s insurance type (Table 1).
Table 1. Health record documentation completion variables extracted to build the models.
|
Feature
|
Value
|
Data Type
|
Number of Category
|
|
Health record documentation completion
|
1= Complete
0= Incomplete
|
Categorical
|
2
|
|
Department
|
Department name
|
Categorical
|
33
|
|
Age
|
Age group of the physicians
(30-39, 40-49, 50-59, >60)
|
Categorical
|
4
|
|
Gender
|
Male, female
|
Categorical
|
2
|
|
Nationality
|
Saudi, Syrian, Egypt, French, Greece, Indian, Jordan, Other Asian, Pakistan, Sudanese.
|
Categorical
|
10
|
|
Year of Discharge
|
2015, 2016,2017, 2018, 2019, 2020, 2021.
|
Categorical
|
7
|
|
Patient insurance type
|
Governmental, private
|
Categorical
|
2
|
Ethical statement
Human subject research was conducted with approval from the governmental hospital’s Institutional Review Board, approval number H- 05- D- 107. The Institutional Review Board at Imam Abdulrahman bin Faisal University also approved the study on November 10, 2021, approval number IRB-PGS-2021-03-422. No consent was required because we aimed to develop a prediction model based only on physicians’ variables.
Analysis
The software used in this data analysis was Orange, which is component-based visual-programming software for data visualization, ML, data mining and data analysis. The first step was retrieving the data for all patients who were discharged during the last seven years, from 2015 to 2021, and extracting it to an Excel sheet.
Rank feature in Orange software was used to demonstrate the most contributing factors to the clinical documentation completion.
The project methodology included several steps: data pre-processing, model development and model evaluation.
Data pre-processing
The data for all discharged patients was extracted from the hospital’s health information system database to an Excel sheet. Patients discharged from January 2015 to August 2021 were included in the study. The data included 106,246 samples, which included 16,239 duplicate values. The duplicates were eventually removed using the “remove duplicates” tool in Excel, so the final data analyzed included 90,007 samples. The data included one target variable, the completion of the EHR documentation, with two values (1, 0) as well as six additional variables: clinical department; the physician’s gender, age, and nationality; the year of discharge and the patient’s insurance type (Table 1).
Developing the learning models
Orange version V3.31.1 was used to build the prediction model. Descriptive statistics for the study features were analyzed using IBM SPSS software version 28.0.1.1 (14). To develop the predictive models, seven classifiers in Orange software were used: random forest, KNN, AdaBoost, neural network, naïve Bayes, logistic regression and SVM.
The random-forest classifier produces a set of decision trees. Every tree is created from a small sample from the training data. When the classifier makes an individual tree, a random subset of attributes is drawn, and then the best attribute is selected19. KNN uses an algorithm to discover the closest training examples in features and uses the average to form the prediction20. AdaBoost is an algorithm that combines weak learners randomly selected from the dataset to make a strong learner19. Neural network is an ML model derived from the human brain. A typical neural network has an input layer, hidden layers and an output layer with different weights between layers and nodes21. Naïve Bayes is based on the Bayes theorem, in which the variables are assumed to be independent. It is a probabilistic classifier that calculates each variable independently against the target class20. Logistic regression is a regression analysis that can be used when the target variable is binary19. SVM is a kernel-based supervised learning algorithm that classifies the data into two or more classes. It is particularly designed for binary classification22. Table 2 presents a brief description of the various classifiers used in this study with their advantages and disadvantages.
Table 2. Classifiers brief description and their advantages and disadvantages.
|
#
|
Classifiers
|
Brief description
|
Advantages
|
Disadvantages
|
|
1
|
Random Forest
|
Random Forest classifier produces a set of decision trees. Every tree is created from a small sample from the training data. When the classifier makes an individual tree, a random subset of attributes is drawn then the best attribute is selected.
|
- Used to solve both classification as well as regression problems
- Less training time with high accuracy
- Efficient in handling non-linear parameters
|
- Complex
- Change greatly with small change in data
|
|
2
|
Neural Network
|
Neural Network is a machine learning model derived from the human brain. A typical neural network has an input layer, hidden layers, and an output layer with different weights between layers and nodes.
|
- Strong in representing complex data
- Good presenting nonlinear relationships between input and output features
|
- Complex
- Data dependant
|
|
3
|
AdaBoost
|
AdaBoost is an algorithm that combines weak learners randomly from the dataset to make a strong learner.
|
- Simple to implement
- Handle both text and numeric data
- Reduces bias and variance
|
- Sensitive to missing values and outliers
- Exposed to noisy data When weak classifier underperforms, the whole model may fail
|
|
4
|
KNN
|
KNN K- Nearest Neighbour uses an algorithm to discover the closest training examples in features and uses the average to form the prediction.
|
- No training period
- Very easy to implement
- New data can be added seamlessly which will not impact the accuracy of the algorithm
|
- Does not work well with large dataset
- Sensitive to missing values and outliers
|
|
5
|
SVM
|
SVM support-vector machine is a kernel-based supervised learning algorithm that classifies the data into two or more classes. SVM is particularly designed for binary classification.
|
- Handles non-linear data efficiently
- Used to solve both classification as well as regression problems
|
- Long training time
- Difficult to interpret
|
|
6
|
Logistic Regression
|
Logistic Regression is a regression analysis that can be used when the target variable is binary.
|
- Easy to use
- Simple to implement
- Perfect fitting on linearly separable datasets
- Overfitting can be reduced by regularization
|
- Effected by outliers
- Boundaries are linear
- Assumes the data is independent
|
|
7
|
Naïve Bayes
|
Naïve Bayes is based on Bayes Theorem, where the variables are assumed to be independent. It is a probabilistic classifier that calculates each variable independently against the target class.
|
- Used small amount of training data
- Training time is less
- Easy to implement
- Mainly targets the text
|
- Does not take into account the number of occurrences of each data.
- Assumes that all predictors are independent
|
Model Evaluation
Model evaluation is an important phase in model development. It explains how well a given classifier is performing. In our data, the target variable was slightly imbalanced, with 60.76 percent for complete documentation and 39.23 percent for incomplete documentation.
Stratified five-folds was used in cross-validation because it is the default parameter shown in Orange. The confusion matrix allows for the identification of misclassified cases or those that are truly classified. With the test and score feature in Orange, the classifiers were evaluated for prediction performance through cross-validation and the area under curve (AUC) score because the accuracy was compared across all classifiers. Performance metrics included AUC as a measurement of the classifier’s ability to distinguish between classes. Higher AUC scores indicate better classifier ability to distinguish between true positives and true negatives. Classification accuracy (CA) is the number of correctly predicted values divided by the number of predictions made: Accuracy = (TN+TP) / (TP+FP+TN+FN). Recall returns the proportion of positive values correctly predicted, which is used to calculate the true positive rate: Recall= TP / (TP + FN). On the other hand, the false-positive rate = FP / (TN + FP). Specificity returns the proportion of negative values correctly predicted: Specificity = TN / (TN + FP). In addition, precision returns the true positives among all the values predicted to be positive: Precision = TP / (TP + FP). Finally, the F1 score is the harmonic mean of precision and recall. It is often used to compare classifiers. F1 score = (2 × Precision × Recall) / (Precision + Recall).
Results
The dataset of 90,007 discharged health records showed 60.8 percent of the final diagnoses in form A were completed and 39.2 percent were not. Male physicians discharged 83.7 percent of the discharged health records, 73.2 percent of the physicians were Saudis, and 59.7 percent were between the ages of 50 and 59. The internal-medicine department had the most discharges, with 22.0 percent. Also, the most discharges occurred in 2019, with 16.2 percent. Most of the discharged patients, 90.1 percent, were on government insurance (Table 3).
Table 3. Result of the descriptive statistics of the study variables.
|
|
Variable
|
Frequency
|
Percent (%)
|
|
Health record documentation completion
|
0
|
35316
|
39.2
|
|
|
1
|
54691
|
60.8
|
|
Gender
|
Female
|
14710
|
16.3
|
|
|
Male
|
75297
|
83.7
|
|
Nationality
|
Egypt
|
8043
|
8.9
|
|
|
French
|
1049
|
1.2
|
|
|
Greece
|
1028
|
1.1
|
|
|
Indian
|
1012
|
1.1
|
|
|
Jordan
|
2511
|
2.8
|
|
|
Other Asian
|
32
|
.0
|
|
|
Pakistan
|
1219
|
1.4
|
|
|
Saudi
|
65865
|
73.2
|
|
|
Sudanese
|
285
|
.3
|
|
|
Syrian
|
8963
|
10.0
|
|
Age Group
|
30-39
|
6436
|
7.2
|
|
|
40-49
|
27064
|
30.1
|
|
|
50-59
|
53703
|
59.7
|
|
|
> 60
|
2804
|
3.1
|
|
Department
|
Anesthesiology
|
477
|
.5
|
|
|
Bariatric Surgery
|
229
|
.3
|
|
|
Chest Surgery
|
747
|
.8
|
|
|
Dental – Advanced Restorative
|
1
|
.0
|
|
|
Dental – Maxillofacial Surgery
|
896
|
1.0
|
|
|
Dental- Pedodontics
|
1864
|
2.1
|
|
|
Dentist General
|
160
|
.2
|
|
|
Dermatology
|
572
|
.6
|
|
|
Cardiac
|
75
|
.1
|
|
|
Endocrinology
|
2867
|
3.2
|
|
|
ENT Surgery
|
4797
|
5.3
|
|
|
Gastroenterology
|
4464
|
5.0
|
|
|
General Surgery
|
17273
|
19.2
|
|
|
Hematology
|
696
|
.8
|
|
|
Infectious Diseases
|
2396
|
2.7
|
|
|
Internal Medicine
|
19835
|
22.0
|
|
|
Nephrology
|
3039
|
3.4
|
|
|
Neurosurgery
|
4125
|
4.6
|
|
|
Neurology
|
3167
|
3.5
|
|
|
Ophthalmology – General
|
1624
|
1.8
|
|
|
Ophthalmology - Glaucoma
|
134
|
.1
|
|
|
Ophthalmology - Pediatric
|
883
|
1.0
|
|
|
Ophthalmology - Retina
|
653
|
.7
|
|
|
Orthopedic surgery
|
8777
|
9.8
|
|
|
Pediatric
|
219
|
.2
|
|
|
Physical Therapy
|
1
|
.0
|
|
|
Plastic Surgery
|
2257
|
2.5
|
|
|
Psychiatry
|
78
|
.1
|
|
|
Pulmonary
|
1036
|
1.2
|
|
|
Rheumatology
|
1431
|
1.6
|
|
|
Trauma Surgery
|
278
|
.3
|
|
|
Urology
|
4365
|
4.8
|
|
|
Vascular
|
591
|
.7
|
|
Year of discharge
|
2015
|
12138
|
13.5
|
|
|
2016
|
13116
|
14.6
|
|
|
2017
|
12446
|
13.8
|
|
|
2018
|
12990
|
14.4
|
|
|
2019
|
14544
|
16.2
|
|
|
2020
|
13308
|
14.8
|
|
|
2021
|
11465
|
12.7
|
|
Patient Insurance
|
Governmental
|
81054
|
90.1
|
|
|
Private
|
8953
|
9.9
|
We used various ML classifiers to predict the clinical-documentation completion. The workflow was executed in Orange (Figure 2). Random forest, KNN, SVM, neural network, naïve Bayes, logistic regression and AdaBoost were the seven ML tools we employed to test the data’s prediction performance. We evaluated each classifier’s performance using the following metrics: the AUC, accuracy, F1 score, precision and recall. In terms of AUC, the result showed that random forest had the highest performance result, with an AUC of 0.891, followed by AdaBoost and neural network models, both with a score of 0.890, but neural network took longer to run than AdaBoost. Table 4 summarizes the metrics used to compare the classifiers’ performance.
When we evaluated AUC metrics, an AUC close to 1 indicated the classifier is the best fit for prediction. The AUC curve (Figure 3) demonstrated the model’s reliability, where true positive was the majority when the value of AUC was near 1. The confusion matrix for the random-forest classifier (Table 5) is another indicator of this algorithm’s usefulness. The true-positive rate was 86.2% (47,149 / 47,149 + 7,542) = (47,149 / 54,691) and the false positive rate was 21.5% (7,580 / 27,736 +7,580) = (7,580 / 35,316). Therefore, the random-forest classifier was the best-fit model to predict EHR documentation incompleteness. Furthermore, the year of patient discharge was the most contributing attribute to the clinical documentation completion followed by the physicians age group and the department as shown in Figure 4.
Figure 2. Orange Workflow.
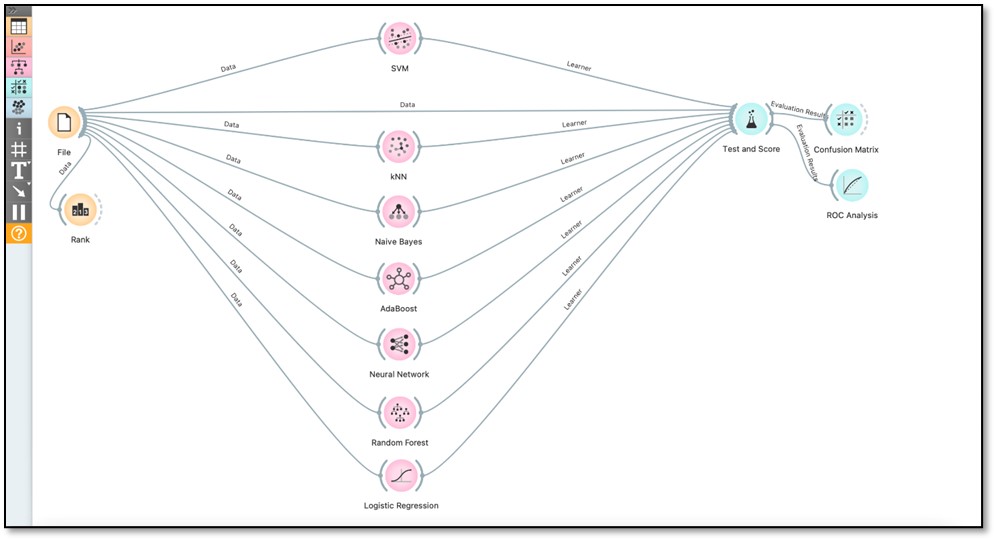
Figure 3. Result of the AUC curve for random forest model using 5-fold cross validation.
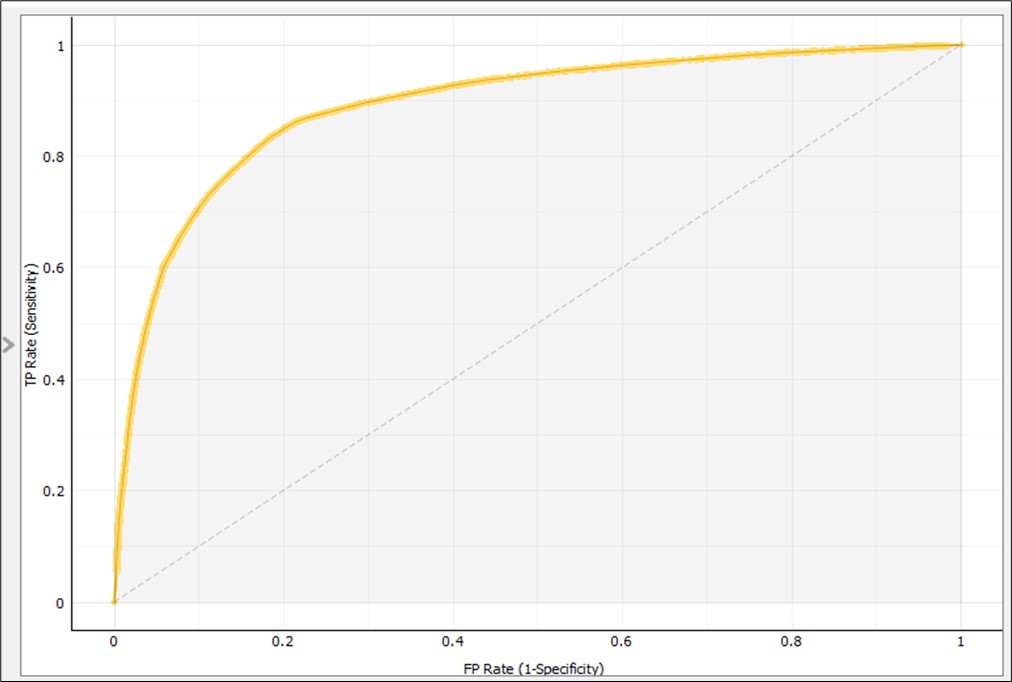
Figure 4. Result of the attributes ranking.
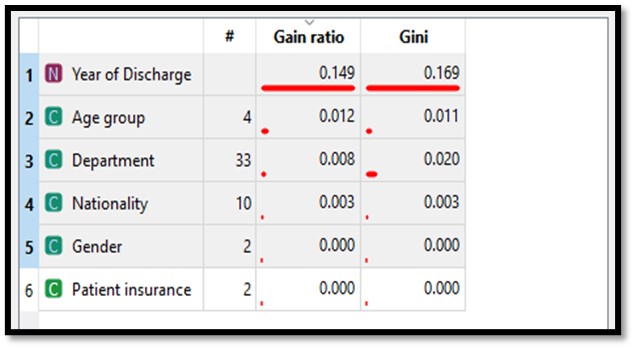
Table 4. Summary Results of all Classifiers showing that random forest is the best fit classifier.
|
Sampling type: Stratified 5- fold Cross validation
|
|
Classifier
|
AUC
|
CA
|
F1 score
|
Precision
|
Recall = sensitivity
|
|
KNN
|
0.853
|
0.817
|
0.817
|
0.817
|
0.817
|
|
SVM
|
0.495
|
0.474
|
0.457
|
0.549
|
0.474
|
|
Random Forest
|
0.891
|
0.831
|
0.831
|
0.831
|
0.831
|
|
Neural Network
|
0.890
|
0.830
|
0.830
|
0.830
|
0.830
|
|
Naïve Bayes
|
0.842
|
0.749
|
0.750
|
0.751
|
0.749
|
|
Logistic Regression
|
0.621
|
0.634
|
0.579
|
0.622
|
0.634
|
|
AdaBoost
|
0.890
|
0.831
|
0.831
|
0.831
|
0.831
|
Table 5. Result of the confusion matrix for random forest classifier.
|
Actual
|
Predicted
|
|
|
0
|
1
|
Sum
|
|
0
|
27736
TN (78.5%)
|
7580
FP (21.5%)
|
35316
|
|
1
|
7542
FN (13.8%)
|
47149
TP (86.2%)
|
54691
|
|
Sum
|
35278
|
54729
|
90007
|
Discussion
We used ML classifiers to predict which physicians are unlikely to complete EHR documentation. In this study, the AUC showed the random-forest model was the best model to predict completion of EHRs. Researchers have used AUC measurement in ML in multiple studies in the healthcare domain to evaluate various classifiers to predict certain health outcomes6,9,11-14,23-26. In various studies using ML, researchers have used clinical documentation in prediction, producing various results. One study showed that random forest was the best-fit model to predict documentation of behavioral change among hypertension patients9. However, other studies have shown other classifiers outperformed random forest in prediction. The completion of discharge documentation in pediatrics helped predict the 30-day readmission rate using a Radiant boosted tree classifier6. Logistic regression showed the best performance to show paramedic documentation to identify opioid and heroin misuse16.
The study's ranking outcome facilitated the comprehension of how various factors influence clinical documentation completion. This insight can be used by hospital management to formulate new policies and procedures to enhance documentation adherence and address this problem. Additionally, the prediction module will provide precise determinations about which physicians may have incomplete documentation, enabling the identification of specific issues on an individual basis through alerts or notifications within the EHR system.
Upon utilizing the ranking feature within the Orange software, it became evident that the year of patient discharge held the most significant influence on documentation completion, although it’s worth noting that this may be influenced by the hospital’s accreditation cycle occurring during that year. Subsequently, the age group of physicians and their respective departments were also influential factors. Notably, physicians between the ages of 50-59 accounted for the highest number of major discharges and displayed the highest level of non-compliance. Examining departments, the internal medicine department stood out with the highest number of discharges, yet regrettably, they also exhibited the highest rate of non-compliant documentation. This underscores the importance of additional training and educational sessions to improve their documentation practices. Health record documentation can be improved through policy creation and implementation27,28. A study showed significant improvement when changes in health record documentation are measured after documentation policy enforcement27. Our findings can help hospital management modify their current policies and procedures related to electronic health documentation to enhance physicians’ documentation adherence.
Current policy in the hospital under study states that physicians who are not compliant in completing their clinical documentation within 30 days of patient discharge are subjected to vacation suspension. The process of handling incomplete health record documentation starts two weeks after the patient’s discharge. Afterward, a notification is sent by email to the head of department and then to the medical administration. But there is still a problem because a physician may not take vacation for few months; as a result, his/her clinical documentation will still not be completed. All these activities happen after the patient has been discharged.
As a result, our model can impede clinical workflow by sending an alert to the health information management department from the onset of patient admission that this treating physician has a high probability of not completing his/her clinical documentation.
Accordingly, a note is sent to that physician and to the head of department and medical administration at the time of patient admission rather than after patient discharge. This policy modification might help treating physicians adhere to policy and complete their documentation on time. We hope over time, more physicians will become more compliant and the norm will be to complete patients’ documentation. This policy modification might lead to better quality control of patients’ clinical documentation and improve healthcare outcomes.
Limitations and Future Work
Our study is the first to use ML approaches to predict health record documentation completion in Saudi Arabia. As such, our findings highlight this approach and methodology’s relevance as a significant tool in the health information management field to improve the physician’s documentation completion through an alert sent to treating physicians who are likely not to complete their EHR documentation at the onset of patient admission. Our study had a few limitations, which could be improved in future studies. Although we studied seven variables, future researchers can expand the number of variables that could increase the prediction accuracy, such as the physician’s shift, degree, and years of experience as well as data from private and government hospitals. Although we used seven attributes in this research, our findings showed promising results in the prediction performance regarding documentation completion.
Conclusion
In this study, the main objective was to develop a ML tool to predict which physicians are not likely to complete health record documentation in the EHR system. The results showed that the random-forest classifier achieved high prediction accuracy over the other classifiers with (AUC = 0.891; F1 and recall score = 0.831). Health record documentation is critical to a patient’s continuous treatment because it is considered a crucial element of patient care. Our results can help hospital management modify their current policies to enhance physicians’ documentation adherence.
References
1. B. McCarthy et al., “Electronic nursing documentation interventions to promote or improve patient safety and quality care: A systematic review,” Journal of Nursing Management, vol. 27, no. 3, pp. 491–501, 2019, doi: 10.1111/jonm.12727.
2. A. Jacob, R. Raj, S. Alagusundaramoorthy, J. Wei, J. Wu, and M. Eng, “Impact of Patient Load on the Quality of Electronic Medical Record Documentation,” Journal of Medical Education and Curricular Development, vol. 8, p. 2382120520988597, Jan. 2021, doi: 10.1177/2382120520988597.
3. R. M. Olsen, O. Hellzén, L. H. Skotnes, and I. Enmarker, “Content of nursing discharge notes: Associations with patient and transfer characteristics,” vol. 2012, Sep. 2012, doi: 10.4236/ojn.2012.23042.
4. D. T. Coghlin et al., “Pediatric Discharge Content: A Multisite Assessment of Physician Preferences and Experiences,” Hospital Pediatrics, vol. 4, no. 1, pp. 9–15, Jan. 2014, doi: 10.1542/hpeds.2013-0022.
5. E. H. Hoyer, C. A. Odonkor, S. N. Bhatia, C. Leung, A. Deutschendorf, and D. J. Brotman, “Association between days to complete inpatient discharge summaries with all-payer hospital readmissions in Maryland,” Journal of Hospital Medicine, vol. 11, no. 6, pp. 393–400, 2016, doi: 10.1002/jhm.2556.
6. H. Zhou et al., “Using machine learning to predict paediatric 30-day unplanned hospital readmissions: a case-control retrospective analysis of medical records, including written discharge documentation,” Aust. Health Review, vol. 45, no. 3, pp. 328–337, Apr. 2021, doi: 10.1071/AH20062.
7. T. L. Wiemken and R. R. Kelley, “Machine Learning in Epidemiology and Health Outcomes Research,” Annu Rev Public Health, vol. 41, pp. 21–36, Apr. 2020, doi: 10.1146/annurev-publhealth-040119-094437.
8. N. Noorbakhsh-Sabet, R. Zand, Y. Zhang, and V. Abedi, “Artificial Intelligence Transforms the Future of Health Care,” The American Journal of Medicine, vol. 132, no. 7, pp. 795–801, Jul. 2019, doi: 10.1016/j.amjmed.2019.01.017.
9. K. Shoenbill, Y. Song, M. Craven, H. Johnson, M. Smith, and E. A. Mendonca, “Identifying Patterns and Predictors of Lifestyle Modification in Electronic Health Record Documentation Using Statistical and Machine Learning Methods,” Prev Med, vol. 136, p. 106061, Jul. 2020, doi: 10.1016/j.ypmed.2020.106061.
10. J. M. Luna et al., “Predicting radiation pneumonitis in locally advanced stage II–III non-small cell lung cancer using machine learning,” Radiotherapy and Oncology, vol. 133, pp. 106–112, Apr. 2019, doi: 10.1016/j.radonc.2019.01.003.
11. L. Turgeman, J. H. May, and R. Sciulli, “Insights from a machine learning model for predicting the hospital Length of Stay (LOS) at the time of admission,” Expert Systems with Applications, vol. 78, pp. 376–385, Jul. 2017, doi: 10.1016/j.eswa.2017.02.023.
12. T. Tunthanathip, S. Sae-heng, T. Oearsakul, I. Sakarunchai, A. Kaewborisutsakul, and C. Taweesomboonyat, “Machine learning applications for the prediction of surgical site infection in neurological operations,” Neurosurgical Focus, vol. 47, no. 2, p. E7, Aug. 2019, doi: 10.3171/2019.5.FOCUS19241.
13. S. B. Golas et al., “A machine learning model to predict the risk of 30-day readmissions in patients with heart failure: a retrospective analysis of electronic medical records data,” BMC Medical Informatics and Decision Making, vol. 18, no. 1, p. 44, Jun. 2018, doi: 10.1186/s12911-018-0620-z.
14. P. Xie et al., “An explainable machine learning model for predicting in-hospital amputation rate of patients with diabetic foot ulcer,” International Wound Journal, vol. 19, no. 4, pp. 910–918, 2022, doi: 10.1111/iwj.13691.
15. J. P. Ridgway, A. Lee, S. Devlin, J. Kerman, and A. Mayampurath, “Machine Learning and Clinical Informatics for Improving HIV Care Continuum Outcomes,” Curr HIV/AIDS Rep, vol. 18, no. 3, pp. 229–236, Jun. 2021, doi: 10.1007/s11904-021-00552-3.
16. J. T. Prieto et al., “The Detection of Opioid Misuse and Heroin Use From Paramedic Response Documentation: Machine Learning for Improved Surveillance,” J Med Internet Res, vol. 22, no. 1, p. e15645, Jan. 2020, doi: 10.2196/15645.
17. A. Chan et al., “Deep learning algorithms to identify documentation of serious illness conversations during intensive care unit admissions,” Palliat Med, vol. 33, no. 2, pp. 187–196, Feb. 2019, doi: 10.1177/0269216318810421.
18. S. M. Slattery, D. C. Knight, D. E. Weese-Mayer, W. A. Grobman, D. C. Downey, and K. Murthy, “Machine learning mortality classification in clinical documentation with increased accuracy in visual-based analyses,” Acta Paediatrica, vol. 109, no. 7, pp. 1346–1353, 2020, doi: 10.1111/apa.15109.
19. G. Shanmugasundar, M. Vanitha, R. Čep, V. Kumar, K. Kalita, and M. Ramachandran, “A Comparative Study of Linear, Random Forest and AdaBoost Regressions for Modeling Non-Traditional Machining,” Processes, vol. 9, no. 11, Art. no. 11, Nov. 2021, doi: 10.3390/pr9112015.
20. I. H. Witten, E. Frank, M. A. Hall, and C. Pal, Data Mining: Practical Machine Learning Tools and Techniques. San Francisco, UNITED STATES: Elsevier Science & Technology, 2016. Accessed: Jul. 15, 2022. [Online]. Available: http://ebookcentral.proquest.com/lib/uodammam-ebooks/detail.action?docID=4708912
21. X. Qi, G. Chen, Y. Li, X. Cheng, and C. Li, “Applying Neural-Network-Based Machine Learning to Additive Manufacturing: Current Applications, Challenges, and Future Perspectives,” Engineering, vol. 5, no. 4, pp. 721–729, Aug. 2019, doi: 10.1016/j.eng.2019.04.012.
22. R. Palaniappan, K. Sundaraj, and S. Sundaraj, “A comparative study of the svm and k-nn machine learning algorithms for the diagnosis of respiratory pathologies using pulmonary acoustic signals,” BMC Bioinformatics, vol. 15, p. 223, 2014, doi: 10.1186/1471-2105-15-223.
23. F. Tezza, G. Lorenzoni, D. Azzolina, S. Barbar, L. A. C. Leone, and D. Gregori, “Predicting in-Hospital Mortality of Patients with COVID-19 Using Machine Learning Techniques,” Journal of Personalized Medicine, vol. 11, no. 5, Art. no. 5, May 2021, doi: 10.3390/jpm11050343.
24. G. Kong, this link will open in a new window Link to external site, K. Lin, and Y. Hu, “Using machine learning methods to predict in-hospital mortality of sepsis patients in the ICU,” BMC Medical Informatics and Decision Making, vol. 20, pp. 1–10, 2020, doi: 10.1186/s12911-020-01271-2.
25. R. Marcinkevics, P. R. Wolfertstetter, S. Wellmann, C. Knorr, and J. E. Vogt, “Using Machine Learning to Predict the Diagnosis, Management and Severity of Pediatric Appendicitis,” Frontiers in Pediatrics, vol. 9, Apr. 2021, doi: 10.3389/fped.2021.662183.
26. Y.-T. Lo, J. C. Liao, M.-H. Chen, C.-M. Chang, and C.-T. Li, “Predictive modeling for 14-day unplanned hospital readmission risk by using machine learning algorithms,” BMC Medical Informatics and Decision Making, vol. 21, no. 1, pp. 1–11, Oct. 2021, doi: 10.1186/s12911-021-01639-y.
27. A. Thoroddsen and M. Ehnfors, “Putting policy into practice: pre- and posttests of implementing standardized languages for nursing documentation,” Journal of Clinical Nursing, vol. 16, no. 10, pp. 1826–1838, 2007, doi: 10.1111/j.1365-2702.2007.01836.x.
28. E. M. Lewiecki et al., “Healthcare Policy Changes in Osteoporosis Can Improve Outcomes and Reduce Costs in the United States,” JBMR Plus, vol. 3, no. 9, Sep. 2019, Accessed: Mar. 29, 2022. [Online]. Available: https://www.proquest.com/docview/2307752133/abstract/2EC97084EC42481FPQ/1
Author Biographies
Alaa Fathi Al Habib (alaa.f.habib@gmail.com) is a Health Information Management Specialist at Health Information Management (Medical Record Department), Dammam Medical Complex, Saudi Arabia.
Hana Mohammed Alharthi (halharthi@iau.edu.sa) is an Associate Professor at Department of Health Information Management & Technology, College of Public Health, Imam Abdulrahman Bin Faisal University, Saudi Arabia.